Pret
Field
Scope
Vision Language model
UI/UX
Credits
Vipin Chandran Pathiyil
Year
2024

Project Overview
Images rely on alt text for accessibility, yet in reality most complex visuals such as graphs, charts, and diagrams rarely have meaningful descriptions.
Pret is a focused vision language model designed to generate clear descriptions for complex visuals, starting with linear graphs.
Built as a proof of concept on limited hardware, it explores how narrowly trained AI can potentially improve visual accessibility for screen reader users, students, and researchers.
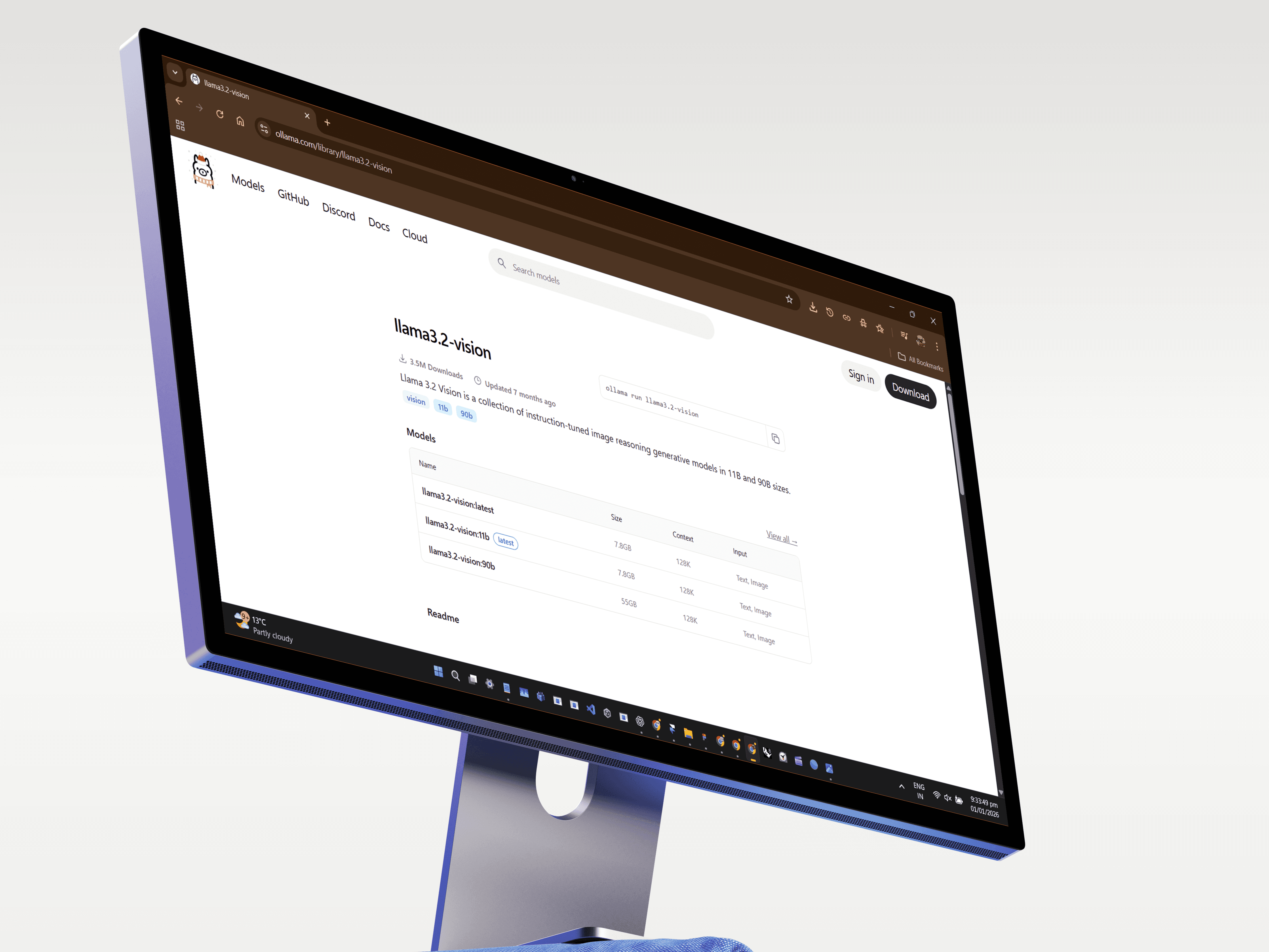
Llama Vision
I selected Llama 3.2 -11b Vision as the base model to fine tune into a focused vision language model.
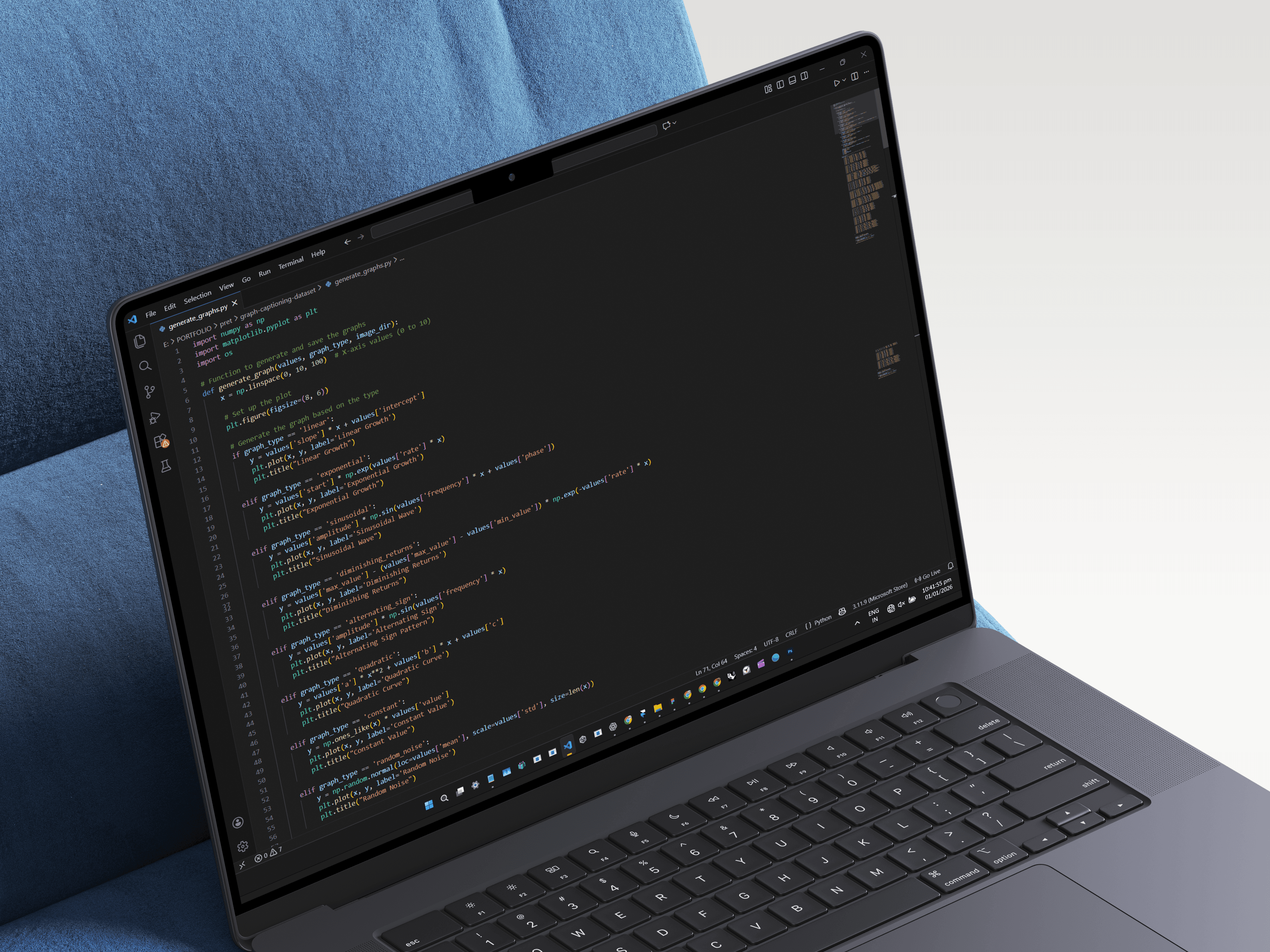
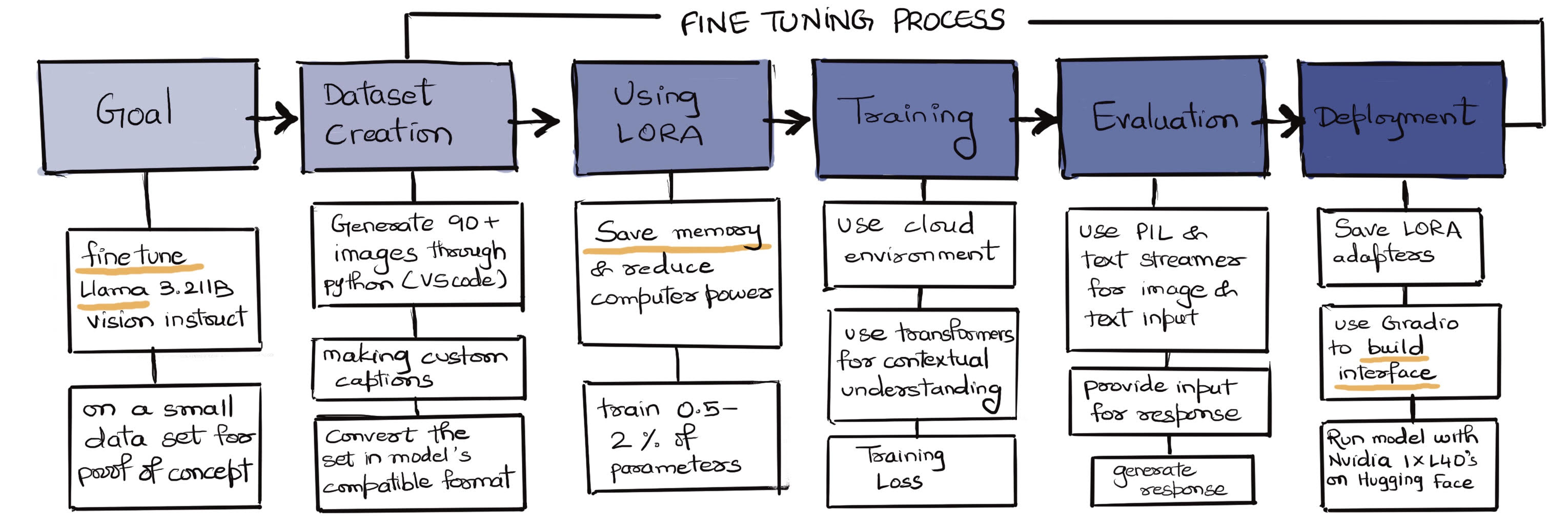
Dataset & Training
I limited the project to linear graphs to keep the model focused and practical as a proof of concept.
generated a structured dataset of 91 linear graph images paired with respective textual descriptions, all produced programmatically.
Click here to explore the training steps.
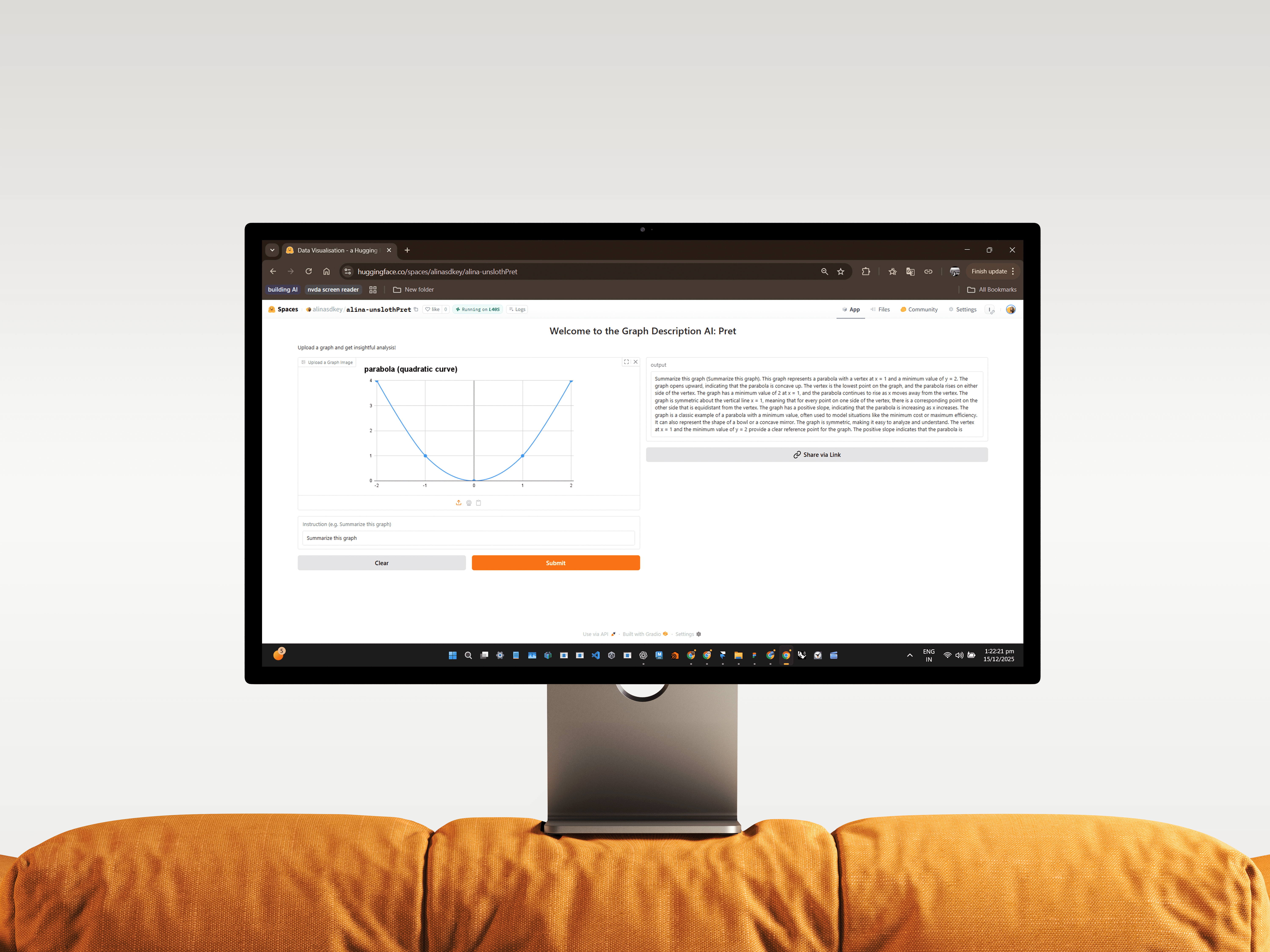
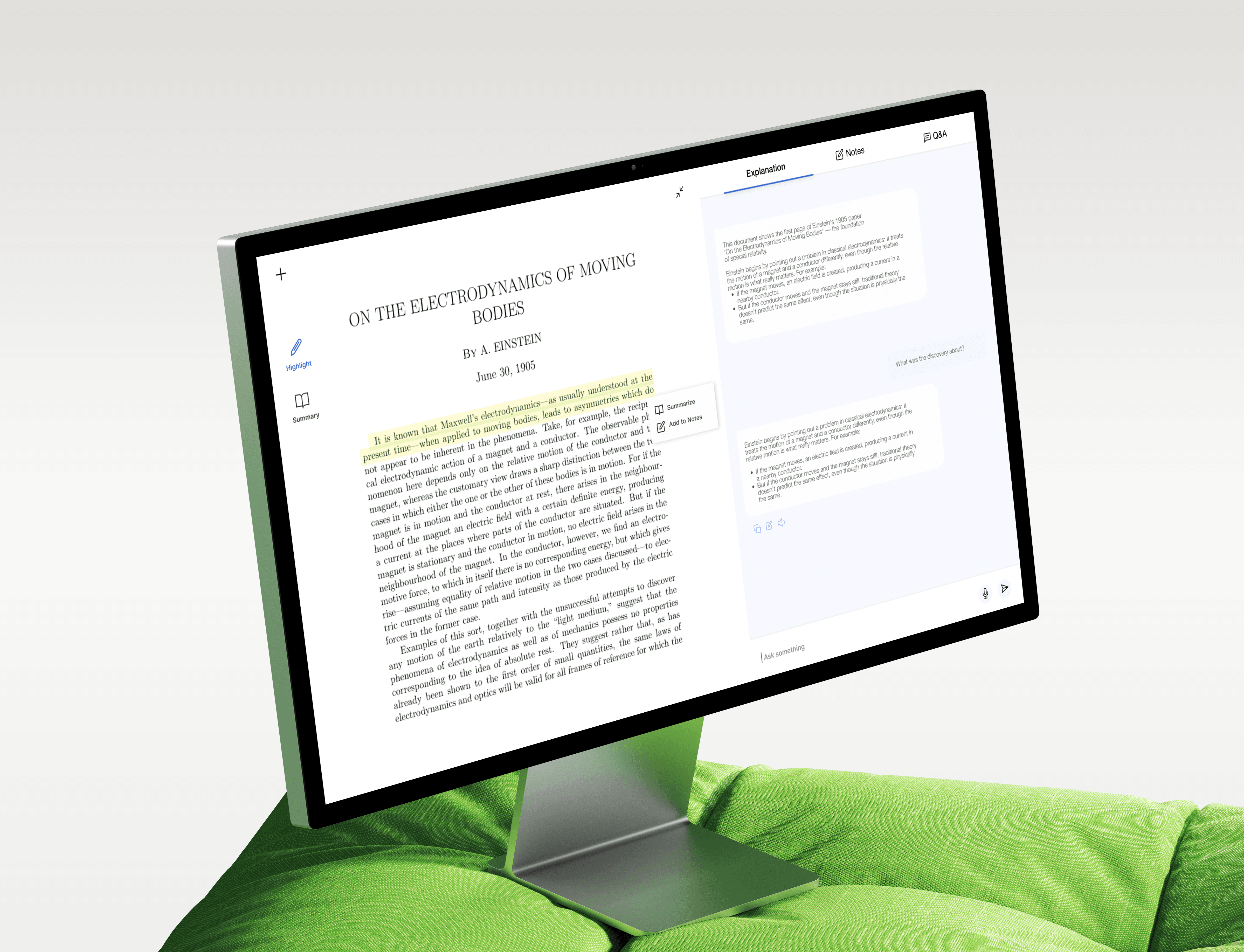
Expanded Usability
Designed a chat based interface to make the model useful for students and researchers.

Result
After the deployment on Hugging Face, 95+ Folks used the dataset and 5 used the model.
I trust this specialized model fills in the gap of detailed alt texts for accessibility.
